class: front .pull-left-wide[ # Estadística Correlacional] .pull-right-narrow[] ## Inferencia, asociación y reporte ---- .pull-left[ ## Juan Carlos Castillo ## Sociología FACSO - UChile ## 2do Sem 2025 ## [.orange[correlacional.netlify.app]](https:/correlacional.netlify.app) ] .pull-right-narrow[ .center[ .content-block-gray[ ## .gray[Sesión 10:] ## .curso[Correlación en ordinales, matrices e índices.]] ] ] --- layout: true class: animated, fadeIn --- class: inverse bottom right # Correlación con variables ordinales --- # Coeficiente de correlación de Spearman - se utiliza para variables ordinales y/o cuando se se violan supuestos de distribución normal - es equivalente a la correlación de Pearson del ranking de las observaciones analizadas - es alta cuando las observaciones tienen un ranking similar --- # Cálculo Spearman - se le asigna un número de ranking a cada valor - el valor más bajo obtiene el mayor ranking, y el más alto el menor - en caso de valores repetidos se produce un "empate", y entonces el ranking se promedia. --- # Ejemplo: variable Educación -- .medium[ .pull-left-narrow[ ``` r data$educ ``` ``` [1] 2 3 4 4 5 7 8 8 ``` Como estos valores están ordenados de menor a mayor, entonces en principio los valores de ranking serían: `8 7 6 5 4 3 2 1`. ] .pull-right-wide[ <br> <br> Pero, hay un par de empates - el valor 4 está repetido y corresponden a los ranking 6 y 5, por lo tanto a ambos se les asigna el promedio de estos rankings: 5,5 - lo mismo sucede con el valor 8 en los rankings 2 y 1, por lo tanto a ambos se les asigna el valor 1,5 ] ] --- count: false .panel1-spearman-auto[ ``` r *data ``` ] .panel2-spearman-auto[ ``` id educ ing mean_educ dif_m_educ dif_m_educ2 mean_ing dif_m_ing 1 1 2 1 5.125 -3.125 9.765625 5.375 -4.375 2 2 3 3 5.125 -2.125 4.515625 5.375 -2.375 3 3 4 3 5.125 -1.125 1.265625 5.375 -2.375 4 4 4 5 5.125 -1.125 1.265625 5.375 -0.375 5 5 5 4 5.125 -0.125 0.015625 5.375 -1.375 6 6 7 7 5.125 1.875 3.515625 5.375 1.625 7 7 8 9 5.125 2.875 8.265625 5.375 3.625 8 8 8 11 5.125 2.875 8.265625 5.375 5.625 dif_m_ing2 dif_xy predict 1 19.140625 13.671875 1.0 2 5.640625 5.046875 2.4 3 5.640625 2.671875 3.8 4 0.140625 0.421875 3.8 5 1.890625 0.171875 5.2 6 2.640625 3.046875 8.0 7 13.140625 10.421875 9.4 8 31.640625 16.171875 9.4 ``` ] --- count: false .panel1-spearman-auto[ ``` r data %>% * select (educ, ing) ``` ] .panel2-spearman-auto[ ``` educ ing 1 2 1 2 3 3 3 4 3 4 4 5 5 5 4 6 7 7 7 8 9 8 8 11 ``` ] --- count: false .panel1-spearman-auto[ ``` r data %>% select (educ, ing) %>% * mutate(., educ_rank=c(8,7,5.5,5.5,4,3,1.5,1.5)) ``` ] .panel2-spearman-auto[ ``` educ ing educ_rank 1 2 1 8.0 2 3 3 7.0 3 4 3 5.5 4 4 5 5.5 5 5 4 4.0 6 7 7 3.0 7 8 9 1.5 8 8 11 1.5 ``` ] --- count: false .panel1-spearman-auto[ ``` r data %>% select (educ, ing) %>% mutate(., educ_rank=c(8,7,5.5,5.5,4,3,1.5,1.5)) %>% * mutate(., ing_rank=c(8,6.5,6.5,4,5,3,2,1)) ``` ] .panel2-spearman-auto[ ``` educ ing educ_rank ing_rank 1 2 1 8.0 8.0 2 3 3 7.0 6.5 3 4 3 5.5 6.5 4 4 5 5.5 4.0 5 5 4 4.0 5.0 6 7 7 3.0 3.0 7 8 9 1.5 2.0 8 8 11 1.5 1.0 ``` ] --- count: false .panel1-spearman-auto[ ``` r data %>% select (educ, ing) %>% mutate(., educ_rank=c(8,7,5.5,5.5,4,3,1.5,1.5)) %>% mutate(., ing_rank=c(8,6.5,6.5,4,5,3,2,1)) *cor(data_spr$educ_rank, data_spr$ing_rank) ``` ] .panel2-spearman-auto[ ``` educ ing educ_rank ing_rank 1 2 1 8.0 8.0 2 3 3 7.0 6.5 3 4 3 5.5 6.5 4 4 5 5.5 4.0 5 5 4 4.0 5.0 6 7 7 3.0 3.0 7 8 9 1.5 2.0 8 8 11 1.5 1.0 ``` ``` [1] 0.9394112 ``` ] <style> .panel1-spearman-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-spearman-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-spearman-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- Cálculo directo en `R`: ``` r cor.test(data$educ, data$ing, "two.sided", "spearman") ``` ``` Spearman's rank correlation rho data: data$educ and data$ing S = 5.0895, p-value = 0.0005311 alternative hypothesis: true rho is not equal to 0 sample estimates: rho 0.9394112 ``` --- class: roja middle center ## El coeficiente de correlación de Spearman no es más que una correlación de Pearson del ranking de las variables --- # Coeficiente de correlación Tau de Kendall .pull-left[ - Recomendado cuando hay un set de datos pequeños y/o cuando hay mucha repetición de observaciones en el mismo ranking - Se basa en una comparación de pares de observaciones concordantes y discordantes ] -- .pull-right[ En `R`: .small[ ``` r cor.test(data$educ, data$ing, "two.sided", "kendall") ``` ``` Kendall's rank correlation tau data: data$educ and data$ing z = 2.9115, p-value = 0.003597 alternative hypothesis: true tau is not equal to 0 sample estimates: tau 0.8680791 ``` ] ] --- ## Tau de Kendall — ejemplo paso a paso (10 pares) **Datos (5 casos ⇒ 10 pares)** .small[ | Caso | X | Y | |:----:|--:|--:| | P1 | 1 | 3 | | P2 | 2 | 1 | | P3 | 3 | 4 | | P4 | 4 | 5 | | P5 | 5 | 2 | ] `\(Pares=\frac{n(n-1)}{2}=\frac{5*4}{2}=10\)` --- ## Enumeración de pares y clasificación .small[ - pares concordantes: van en la misma dirección - pares discordantes: van en la dirección contraria ] .tiny[ | # | Par | (Xi, Yi) | (Xj, Yj) | ΔX | ΔY | sgn(ΔX) | sgn(ΔY) | Clasificación | |--:|:-------:|:--------:|:--------:|:---:|:---:|:-------:|:-------:|:-------------| | 1 | (P1,P2) | (1,3) | (2,1) | +1 | -2 | + | - | Discordante | | 2 | (P1,P3) | (1,3) | (3,4) | +2 | +1 | + | + | Concordante | | 3 | (P1,P4) | (1,3) | (4,5) | +3 | +2 | + | + | Concordante | | 4 | (P1,P5) | (1,3) | (5,2) | +4 | -1 | + | - | Discordante | | 5 | (P2,P3) | (2,1) | (3,4) | +1 | +3 | + | + | Concordante | | 6 | (P2,P4) | (2,1) | (4,5) | +2 | +4 | + | + | Concordante | | 7 | (P2,P5) | (2,1) | (5,2) | +3 | +1 | + | + | Concordante | | 8 | (P3,P4) | (3,4) | (4,5) | +1 | +1 | + | + | Concordante | | 9 | (P3,P5) | (3,4) | (5,2) | +2 | -2 | + | - | Discordante | |10 | (P4,P5) | (4,5) | (5,2) | +1 | -3 | + | - | Discordante | ] --- **Conteo:** - Concordantes \(C = 6\) → 2,3,5,6,7,8 - Discordantes \(D = 4\) → 1,4,9,10 - Empates \(T_x = 0\), \(T_y = 0\) --- ## Cálculo de `\(\tau\)` .small[ Número total de pares: `\(C + D + \text{(empates)} = 6 + 4 + 0 = 10\)`. **Tau-a (sin empates):** $$ \tau_a = \frac{C - D}{pares} = \frac{6 - 4}{10} = 0.20 $$ **Tau-b (corrige empates):** $$ \tau_b = \frac{C - D}{\sqrt{(C + D + T_x)(C + D + T_y)}} = \frac{6 - 4}{\sqrt{(10 + 0)(10 + 0)}} = 0.20 $$ **Interpretación:** `\(\tau = 0.20\)` indica una asociación positiva **débil**: hay más pares que mantienen el orden entre `\(X\)` y `\(Y\)` que pares que lo invierten. ] --- class: inverse ## Recomendaciones generales - Pearson es el coeficiente de correlación por defecto - En caso de datos en escala de medición ordinal se puede aplicar Spearman (aunque Pearson es también aceptado en este contexto). - Kendall se reporta en casos muy específicos donde hay un set de datos pequeños y repetición de observaciones en el mismo ranking ("empates") --- class: inverse bottom right # Matrices de correlación --- # Matriz de correlación - una matriz de correlación se conforma cuando se representa simultaneamente más de un par de asociaciones bivariadas -- - por ejemplo, si agregamos la variable edad a nuestra base de datos: ``` r data$edad <- c(50, 65, 27, 15, 40, 22, 25, 38) ``` Tenemos .red[3 variables], y por lo tanto los siguentes pares de correlaciones posibles: ingreso-educación, ingreso-edad, y educación-edad --- count: false .panel1-matriz1-auto[ ``` r *cor_mat <- data ``` ] .panel2-matriz1-auto[ ] --- count: false .panel1-matriz1-auto[ ``` r cor_mat <- data %>% * select(educ, ing, edad) ``` ] .panel2-matriz1-auto[ ] --- count: false .panel1-matriz1-auto[ ``` r cor_mat <- data %>% select(educ, ing, edad) %>% * cor(.) ``` ] .panel2-matriz1-auto[ ] --- count: false .panel1-matriz1-auto[ ``` r cor_mat <- data %>% select(educ, ing, edad) %>% cor(.) *cor_mat ``` ] .panel2-matriz1-auto[ ``` educ ing edad educ 1.0000000 0.9512367 -0.4704649 ing 0.9512367 1.0000000 -0.4058455 edad -0.4704649 -0.4058455 1.0000000 ``` ] --- count: false .panel1-matriz1-auto[ ``` r cor_mat <- data %>% select(educ, ing, edad) %>% cor(.) cor_mat *round(cor_mat, 3) ``` ] .panel2-matriz1-auto[ ``` educ ing edad educ 1.0000000 0.9512367 -0.4704649 ing 0.9512367 1.0000000 -0.4058455 edad -0.4704649 -0.4058455 1.0000000 ``` ``` educ ing edad educ 1.000 0.951 -0.470 ing 0.951 1.000 -0.406 edad -0.470 -0.406 1.000 ``` ] --- count: false .panel1-matriz1-auto[ ``` r cor_mat <- data %>% select(educ, ing, edad) %>% cor(.) cor_mat round(cor_mat, 3) *sjPlot::tab_corr(cor_mat) ``` ] .panel2-matriz1-auto[ ``` educ ing edad educ 1.0000000 0.9512367 -0.4704649 ing 0.9512367 1.0000000 -0.4058455 edad -0.4704649 -0.4058455 1.0000000 ``` ``` educ ing edad educ 1.000 0.951 -0.470 ing 0.951 1.000 -0.406 edad -0.470 -0.406 1.000 ``` <table style="border-collapse:collapse; border:none;"> <tr> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;"> </th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">educ</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">ing</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">edad</th> </tr> <tr> <td style="font-style:italic;">educ</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.951</td> <td style="padding:0.2cm; text-align:center;">-0.470</td> </tr> <tr> <td style="font-style:italic;">ing</td> <td style="padding:0.2cm; text-align:center;">0.951</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">-0.406</td> </tr> <tr> <td style="font-style:italic;">edad</td> <td style="padding:0.2cm; text-align:center;">-0.470</td> <td style="padding:0.2cm; text-align:center;">-0.406</td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td colspan="4" style="border-bottom:double black; border-top:1px solid black; font-style:italic; font-size:0.9em; text-align:right;">Computed correlation used pearson-method with listwise-deletion.</td> </tr> </table> ] <style> .panel1-matriz1-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz1-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz1-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- # Matriz de correlación(es) - tabla de doble entrada donde las variables se presentan tanto en las filas como en las columnas -- - el coeficiente de correlación correspondiente al par de variables aparece en la intersección de las columnas -- - existe información redundante - las correlaciones se repiten, dado que las variables se intersectan dos veces en la tabla - la diagonal tiene solo unos (1), ya que es la correlación de la variable consigo misma --- count: false # Ajustando tabla sjPlot::tab_corr .panel1-matriz2-auto[ ``` r *sjPlot::tab_corr(cor_mat, * triangle = "lower", * title = "Tabla de correlaciones del ejemplo" * ) ``` ] .panel2-matriz2-auto[ <table style="border-collapse:collapse; border:none;"> <caption style="font-weight: bold; text-align:left;">Tabla de correlaciones del ejemplo</caption> <tr> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;"> </th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">educ</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">ing</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">edad</th> </tr> <tr> <td style="font-style:italic;">educ</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">ing</td> <td style="padding:0.2cm; text-align:center;">0.951</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">edad</td> <td style="padding:0.2cm; text-align:center;">-0.470</td> <td style="padding:0.2cm; text-align:center;">-0.406</td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td colspan="4" style="border-bottom:double black; border-top:1px solid black; font-style:italic; font-size:0.9em; text-align:right;">Computed correlation used pearson-method with listwise-deletion.</td> </tr> </table> ] <style> .panel1-matriz2-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz2-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz2-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> <br> --- count: false # Matriz con librería corrplot .panel1-matriz3-auto[ ``` r *library(corrplot) ``` ] .panel2-matriz3-auto[ ] --- count: false # Matriz con librería corrplot .panel1-matriz3-auto[ ``` r library(corrplot) *corrplot(cor_mat) ``` ] .panel2-matriz3-auto[ 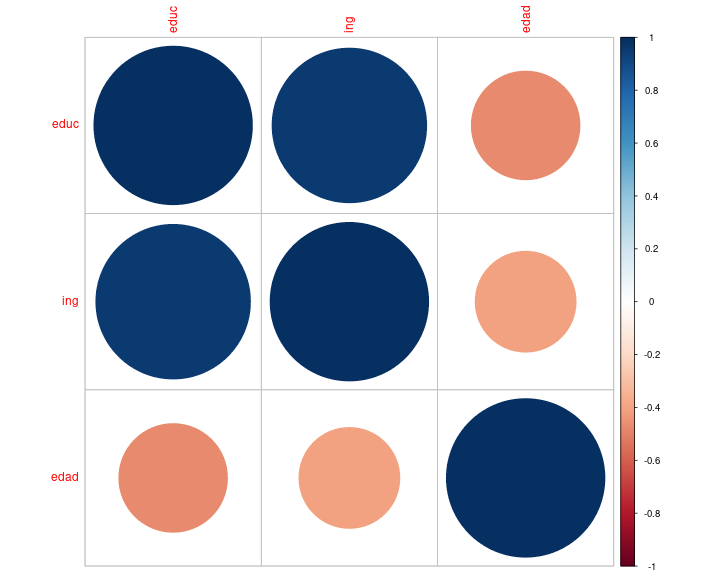<!-- --> ] <style> .panel1-matriz3-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz3-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz3-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- count: false # Matriz con librería corrplot .panel1-matriz31-auto[ ``` r *corrplot(cor_mat, * method = 'number') ``` ] .panel2-matriz31-auto[ 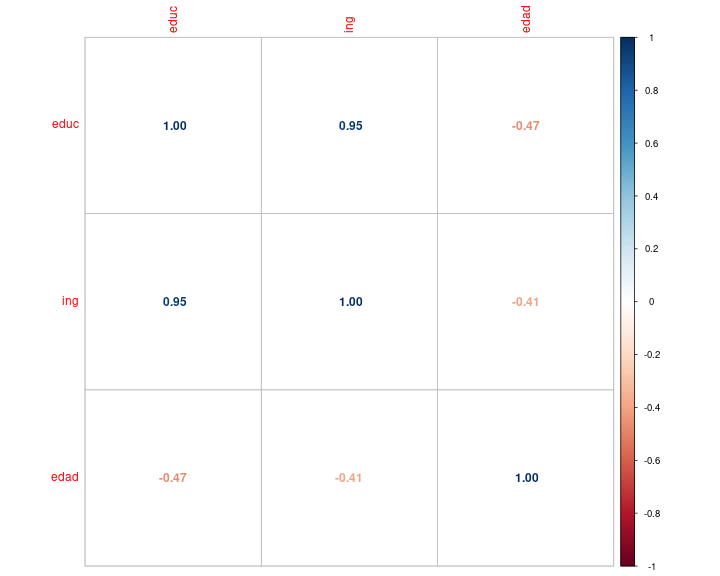<!-- --> ] <style> .panel1-matriz31-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz31-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz31-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- count: false # corrplot .panel1-matriz4-auto[ ``` r *corrplot(cor_mat, * method = 'number', * type = 'lower', * number.cex = 3, * tl.cex = 3, * diag = FALSE) ``` ] .panel2-matriz4-auto[ 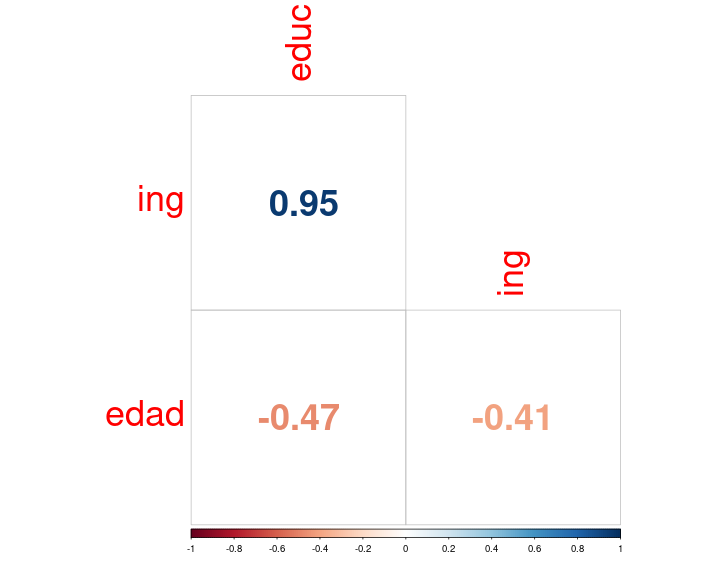<!-- --> ] <style> .panel1-matriz4-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz4-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz4-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- count: false # corrplot.mixed .panel1-matriz5-auto[ ``` r *corrplot.mixed(cor_mat, * lower = "number", * upper = "circle", * number.cex = 3, * tl.cex = 3, * diag = "n") ``` ] .panel2-matriz5-auto[ <!-- --> ] <style> .panel1-matriz5-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz5-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz5-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- count: false # corrplot.mixed .panel1-matriz6-auto[ ``` r *corrplot(cor_mat, * type = "lower", * addCoef.col = 'white', * number.cex = 3, * tl.cex = 3, * diag = FALSE) ``` ] .panel2-matriz6-auto[ <!-- --> ] <style> .panel1-matriz6-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz6-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz6-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- count: false # corrplot.mixed .panel1-matriz7-auto[ ``` r *corrplot(cor_mat, * type = "lower", * addCoef.col = 'white', * number.cex = 3, * tl.cex = 3, * diag = FALSE, * method = 'square') ``` ] .panel2-matriz7-auto[ <!-- --> ] <style> .panel1-matriz7-auto { color: black; width: 38.6060606060606%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel2-matriz7-auto { color: black; width: 59.3939393939394%; hight: 32%; float: left; padding-left: 1%; font-size: 80% } .panel3-matriz7-auto { color: black; width: NA%; hight: 33%; float: left; padding-left: 1%; font-size: 80% } </style> --- class: inverse bottom right # Correlaciones, matrices, y casos perdidos --- # Consideraciones sobre casos perdidos - Cuando hay casos perdidos en las variables, ¿cuál es el número de casos de la matriz de correlaciones? - Las correlaciones bivariadas se calculan con información completa, por lo tanto si hay un dato perdido en una de las variables se elimina el caso completo - Algunas funciones lo hacen de manera automática, en otras hay que especificarlo previamente --- # Ejemplo Agreguemos un caso perdido (NA en R) a una de nuestras variables ``` r data$edad ``` ``` [1] 50 65 27 15 40 22 25 38 ``` ``` r data$edad <-replace(data$edad, data$edad==15, NA) data$edad ``` ``` [1] 50 65 27 NA 40 22 25 38 ``` --- .medium[ ``` r cormat_NA <- data %>% select(educ, ing, edad) %>% cor(.) round(cormat_NA,3) ``` ``` educ ing edad educ 1.000 0.951 NA ing 0.951 1.000 NA edad NA NA 1 ``` ``` r cormat_listwise <- data %>% select(educ, ing, edad) %>% cor(., use = "complete.obs") round(cormat_listwise, 3) ``` ``` educ ing edad educ 1.000 0.962 -0.669 ing 0.962 1.000 -0.494 edad -0.669 -0.494 1.000 ``` ] --- # Eliminación de casos perdidos por lista (o listwise) - las correlaciones bivariadas requieren eliminación de casos perdidos tipo listwise, es decir, si hay un dato perdido en una variable se pierde el caso completo - Para conocer el número de casos con que se calculó la matriz: .medium[ ``` r sum(complete.cases(data)) ``` ``` [1] 7 ``` ] Por lo tanto, en el cálculo se perdió el caso o fila completa de la base (de 8 casos) que tenía el caso perdido. --- # Eliminación de casos perdidos por pares (o pairwise) - en el caso de las matrices de correlaciones es posible tomar la opción .red[pairwise] para casos perdidos - pairwise quiere decir que se eliminan los casos perdidos solo cuando afectan al cálculo de un **par específico**. --- # Eliminación de casos perdidos por pares (o pairwise) - en el caso de nuestro ejemplo, si consideramos listwise todas las correlaciones tienen 7 casos, pero con pairwise la correlación entre educación e ingreso mantendría 8 casos. - por lo tanto, **pairwise permite mayor rescate de información y mayor N en el cálculo de matrices de correlaciones** --- # Opción pairwise en correlación en R ``` r data %>% select(educ, ing, edad) %>% cor(., use = "pairwise") ``` ``` educ ing edad educ 1.0000000 0.9512367 -0.6693607 ing 0.9512367 1.0000000 -0.4941732 edad -0.6693607 -0.4941732 1.0000000 ``` En este caso vemos una leve variación en el coeficiente comprometido (educ-ing) comparando listwise con pairwise --- # Número de casos pairwise ``` r data %>% select(educ,ing,edad) %>% psych::pairwiseCount() ``` ``` educ ing edad educ 8 8 7 ing 8 8 7 edad 7 7 7 ``` Se indica que en las correlaciones con edad se utilizaron 7 casos, mientras en la correlación entre ingreso y educación se utilizan 8 casos con el método pairwise --- class: inverse bottom right # Baterías, matrices y consistencia --- class: middle center .center[  ] --- class: middle .pull-left-narrow[ # Preguntas y error de medición ] .pull-right-wide[ .content-box-yellow[ - Para medir hechos observables simples usualmente se utiliza **una pregunta** (ej: edad) - Fenómenos complejos se miden en general con más de una pregunta, con el objetivo de dar mejor cuenta del atributo (i.e. minimizar error de medición) ]] --- # Baterías de indicadores múltiples - en general las encuestas suelen incluir varias preguntas respecto de un mismo tema -> .red[baterías de indicadores múltiples] -- - cubren distintos aspectos de un mismo fenómeno complejo que no se agota en solo un indicador -> minimiza .red[error de medición] -- - .red[problema]: ¿cómo se analizan indicadores que están relacionados?¿cómo se muestran los resultados? --- # Análisis de indicadores en baterías .pull-left-narrow[ 1. .red[Univariado]: se sugiere presentar análisis descriptivos que contengan todos los indicadores para poder comparar frecuencias ] .pull-right-wide[ .center[  .small[(likert plot, `sjPlot`)] ] ] --- # Análisis de indicadores en baterías .pull-left-narrow[ 2\. .red[Bivariado]: tablas/gráficos de correlaciones (`corrplot`) ] .pull-right-wide[ .center[  ] ] --- # Análisis de indicadores en baterías - Se podría asumir un concepto o .red[dimensión subyacente] a la batería de items - Para facilitar el avance en el análisis (por ejemplo, relacionar ese concepto subyacente con otras variables), muchas veces se reduce la batería a algún .red[tipo de índice (sumativo/promedio)] - ¿Podemos asegurar que los items están realmente .red[midiendo lo mismo]? --- ## ¿Miden lo mismo? .center[  ] --- class: middle .pull-left-narrow[ # Preguntas y error de medición ] .pull-right-wide[ .content-box-red[ - En este marco se asume que el **indicador es distinto del atributo**, y que la medición del atributo o variable latente conlleva error - Cuando la el atributo se mide con más de una pregunta, se puede intentar estimar la **variable latente** mediante índices o técnicas de **análisis factorial** ]] --- # Medición y error .pull-left[ .center[  ] ] .pull-right[ - antes de agrupar indicadores en un índice hay que evaluar si los indicadores se encuentran relacionados - -> si miden constructos similares - -> si la medición es .red[confiable] ] --- class: inverse center <br> .content-box-red[ ## .red[¿Cómo estimar el nivel de relación entre indicadores que miden un mismo constructo?] ] -- ### Distintas maneras, pero todas se basan en la técnica de la .red[correlación] --- # Matriz de correlaciones (1) .center[  Matriz hipotética de indicadores que miden un mismo constructo ] --- # Ej. Matriz de correlaciones (2) .center[  Matriz hipotética de indicadores que miden constructos independientes ] --- # Ej. Matriz de correlaciones (3) .center[  Matriz hipotética de variables que miden dos constructos independientes] --- class: inverse ## .yellow[Entonces:] ### 1. analizar la .red[matriz de correlaciones] antes de generar cualquier técnica de reducción de información (ej: crear índice) ### 2. evaluar la posibilidad de generación algún tipo de .red[índice] que resuma la información --- # Datos ejemplo - batería atribuciones de pobreza, encuesta "Desigualdad, Justicia y Participación Política" - FONDECYT Iniciación 11121203 (2013-2015) [Social justice and citizenship participation](https://jc-castillo.com/project/fondecyt-iniciacion/) .center[  ] --- .small[ | |var |label | n| NA.prc| mean| sd|range | |:--|:-------|:----------------------------------|----:|--------:|--------:|--------:|:-------| |2 |falthab |Razones pobreza falta de habilidad | 1228| 1.365462| 2.630293| 1.254220|4 (1-5) | |3 |malasue |Razones pobreza mala suerte | 1227| 1.445783| 2.019560| 1.140079|4 (1-5) | |1 |faltesf |Razones pobreza falta de esfuerzo | 1238| 0.562249| 3.155897| 1.290758|4 (1-5) | |4 |sisecon |Razones pobreza sistema económico | 1218| 2.168675| 4.036946| 1.095047|4 (1-5) | |5 |siseduc |Razones pobreza sistema educativo | 1227| 1.445783| 4.088835| 1.088767|4 (1-5) | ] --- ## Matriz de correlaciones ``` r cormat <- cor(data) cormat ``` ``` falthab malasue faltesf sisecon siseduc falthab 1 NA NA NA NA malasue NA 1 NA NA NA faltesf NA NA 1 NA NA sisecon NA NA NA 1 NA siseduc NA NA NA NA 1 ``` Esta función no resulta ya que requiere que no existan casos perdidos --- ## Matriz de correlaciones Entonces: ``` r cormat <- cor(na.omit(data)) cormat ``` ``` falthab malasue faltesf sisecon siseduc falthab 1.000000000 0.31793357 0.36246039 -0.02787884 -0.005893529 malasue 0.317933565 1.00000000 0.16936872 0.02755708 0.013865045 faltesf 0.362460395 0.16936872 1.00000000 -0.06579454 -0.020114542 sisecon -0.027878843 0.02755708 -0.06579454 1.00000000 0.593625639 siseduc -0.005893529 0.01386504 -0.02011454 0.59362564 1.000000000 ``` --- ## Matriz de correlaciones (Formato publicable) .tiny[ ``` r tab_corr(data) ``` <table style="border-collapse:collapse; border:none;"> <tr> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;"> </th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza falta de habilidad</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza mala suerte</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza falta de esfuerzo</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza sistema económico</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza sistema educativo</th> </tr> <tr> <td style="font-style:italic;">Razones pobreza falta de habilidad</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.318<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.362<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.028<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.006<span style="vertical-align:super;font-size:0.8em;"></span></td> </tr> <tr> <td style="font-style:italic;">Razones pobreza mala suerte</td> <td style="padding:0.2cm; text-align:center;">0.318<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.169<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">0.028<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">0.014<span style="vertical-align:super;font-size:0.8em;"></span></td> </tr> <tr> <td style="font-style:italic;">Razones pobreza falta de esfuerzo</td> <td style="padding:0.2cm; text-align:center;">0.362<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.169<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">-0.066<span style="vertical-align:super;font-size:0.8em;">*</span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.020<span style="vertical-align:super;font-size:0.8em;"></span></td> </tr> <tr> <td style="font-style:italic;">Razones pobreza sistema económico</td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.028<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">0.028<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center;">-0.066<span style="vertical-align:super;font-size:0.8em;">*</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.594<span style="vertical-align:super;font-size:0.8em;">***</span></td> </tr> <tr> <td style="font-style:italic;">Razones pobreza sistema educativo</td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.006<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">0.014<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.020<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center;">0.594<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td colspan="6" style="border-bottom:double black; border-top:1px solid black; font-style:italic; font-size:0.9em; text-align:right;">Computed correlation used pearson-method with listwise-deletion.</td> </tr> </table> ] --- .pull-left-narrow[ ## Matriz de correlaciones - gráfico ``` r corrplot(cormat) ``` ] .pull-left-wide[ <!-- --> ] --- .pull-left-narrow[ ## Matriz de correlaciones - gráfico ajustado .small[ ``` r corrplot::corrplot(cormat, method = "color", addCoef.col = "#000390", type = "upper", tl.col = "black", col=colorRampPalette(c("white","#0068DC"))(8), bg = "white", na.label = "-") ``` ]] .pull-right-wide[ .center[ <!-- --> ] ] --- class: inverse bottom right ## .red[Hacia la construcción de un índice] --- # Alpha de Cronbach - índice de consistencia interna de una batería - en general, interpretable como la correlación [absoluta] promedio entre distintas variables que componen una batería de medición - varía entre **0 y 1**; valores más cercanos a 1 indican mayor consistencia - en general valores sobre 0.6 se consideran aceptables --- # Alpha de Cronbach .pull-left[ - funcion alpha de la librería `psych` - se genera un objeto (lo llamaremos alpha). Contiene bastante información, por ahora nos enfocaremos solo en el valor de alpha (`raw_alpha`) ] .pull-right[ .small[ ``` r names(data) ``` ``` [1] "falthab" "malasue" "faltesf" "sisecon" "siseduc" ``` ``` r alpha <-psych::alpha(data) ``` ``` Some items ( falthab malasue faltesf ) were negatively correlated with the first principal component and probably should be reversed. To do this, run the function again with the 'check.keys=TRUE' option ``` ``` r alpha$total$raw_alpha ``` ``` [1] 0.4363206 ``` ] ] --- # Alpha de Cronbach - puntaje 0.43, por lo tanto bajo los valores aceptables de consistencia interna - esto ya se podía anticipar desde la matriz de correlaciones, que aparentemente mostraba dos dimensiones subyacentes a la batería - además, se genera un mensaje de advertencia sobre posibles items codificados a la inversa (dada la correlación entre items de dimensiones distintas) --- # Opciones - construcción de índices basados en la información de la matriz de correlaciones - análisis factorial --- class: inverse bottom right # .red[Construcción de índices] --- # Índice promedio - vamos a generar 2 índices a partir de esta batería: uno para atribución interna (falthab,faltesf,malasue) y otro para externa (sisecon,siseduc) - tema valores perdidos: - para perder el mínimo de casos se recomienda realizar índice aún con casos que no hayan respondido algún item - ya que esto distorsionaría el puntaje si fuera sumado, se hace un índice promedio, especificando que se calcule aún con valores perdidos --- Indice de atribución interna y externa (promedios) ``` r data <- cbind(data, "interna_prom"=rowMeans(data %>% select(falthab,faltesf,malasue), na.rm=TRUE)) data <- cbind(data, "externa_prom"=rowMeans(data %>% select(sisecon,siseduc), na.rm=TRUE)) names(data) ``` ``` [1] "falthab" "malasue" "faltesf" "sisecon" [5] "siseduc" "interna_prom" "externa_prom" ``` --- class: inverse ## _Resumen_ .medium[ ### - Correlación de Spearman: apropiada para variables ordinales, equivale a la correlación de Pearson del ranking de las variables ### - Matriz de correlaciones: forma tradicional de reporte de asociaciones de las variables de una investigación, importante considerar tratamiento de datos perdidos (listwise o pairwise) ] ### - Índices y consistencia interna en matrices --- class: front .pull-left-wide[ # Estadística Correlacional] .pull-right-narrow[] ## Inferencia, Asociación y reporte ---- .pull-left[ ## Juan Carlos Castillo ## Sociología FACSO - UChile ## 2do Sem 2025 ## [.orange[correlacional.netlify.com]](https://encuestas-sociales.netlify.com) ] <!-- adjust font size in this css code chunk for flipbook, currently 80 -->