El objetivo de esta guía práctica es introducirnos en la inferencia estadística, revisando los conceptos y aplicaciones de la curva normal y las probabilidades bajo esta con puntajes Z, además del cálculo de intervalos de confianza.
En detalle, aprenderemos y recordaremos:
Los conceptos de promedio y desviación estándar
Estimación de puntaje Z
Cómo calcular e interpretar intervalos de confianza
Revisión básica de R y RStudio
Antes de comenzar, repasemos algunos puntos clave:
Estructura de RStudio
Consola: aquí se pueden escribir y ejecutar comandos de manera directa.
Archivo de código (.R o .qmd): permite guardar el código, comentarios y reproducir el análisis.
Ejecutar código:
Selecciona la línea y presiona Ctrl + Enter (Windows/Linux) o Cmd + Enter (Mac).
También puedes ejecutar un bloque completo con el botón Run.
Comentarios: se escriben con #. Todo lo que sigue en la línea después de # no se ejecuta.
Atajos útiles:
Ctrl + Shift + C: comentar o descomentar líneas seleccionadas.
Ctrl + Shift + J: Añade pipe %>%
Ctrl + L: limpiar la consola.
Librerías
Cargaremos algunas librerías que serán necesarias en las diferentes partes de esta guía práctica:
pacman::p_load permite instalarlas automáticamente si no las tienes.
if (!require("pacman")) install.packages("pacman") # instalar pacman
Loading required package: pacman
pacman::p_load(dplyr, # para sintaxis Publish) # para IC) options(scipen =999) # para desactivar notacion cientificarm(list =ls()) # para limpiar el entorno de trabajo
¿Qué es un vector en R?
En R, un vector es la estructura de datos más básica:
Es una colección ordenada de valores del mismo tipo (números, caracteres o lógicos).
Por ejemplo, una columna en una base de datos
1. Promedio y desviación estándar
El promedio y la desviación estándar son conceptos fundamentales para continuar hacia la estadística inferencial. Repasemos estos conceptos mediante un ejercicio con datos simulados.
Primero, generaremos un vector de 100 valores aleatorios con \(\mu = 5\) y \(\sigma = 2\), y lo visualizaremos con la función print.
set.seed(123) # Fijar la semilla para reproducibilidadvector <-rnorm(100, mean =5, sd =2)print(vector) # Ver el vector generado
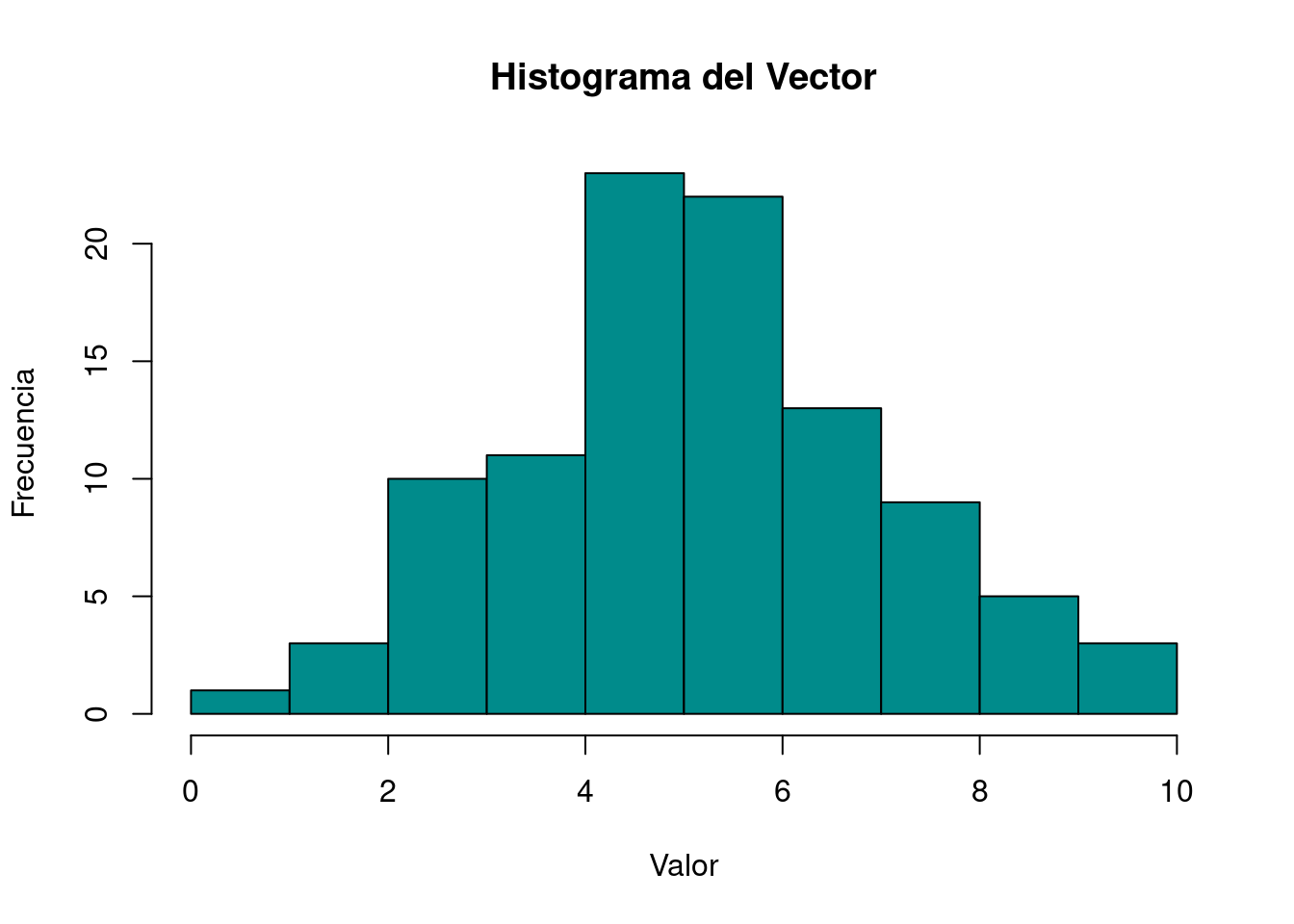
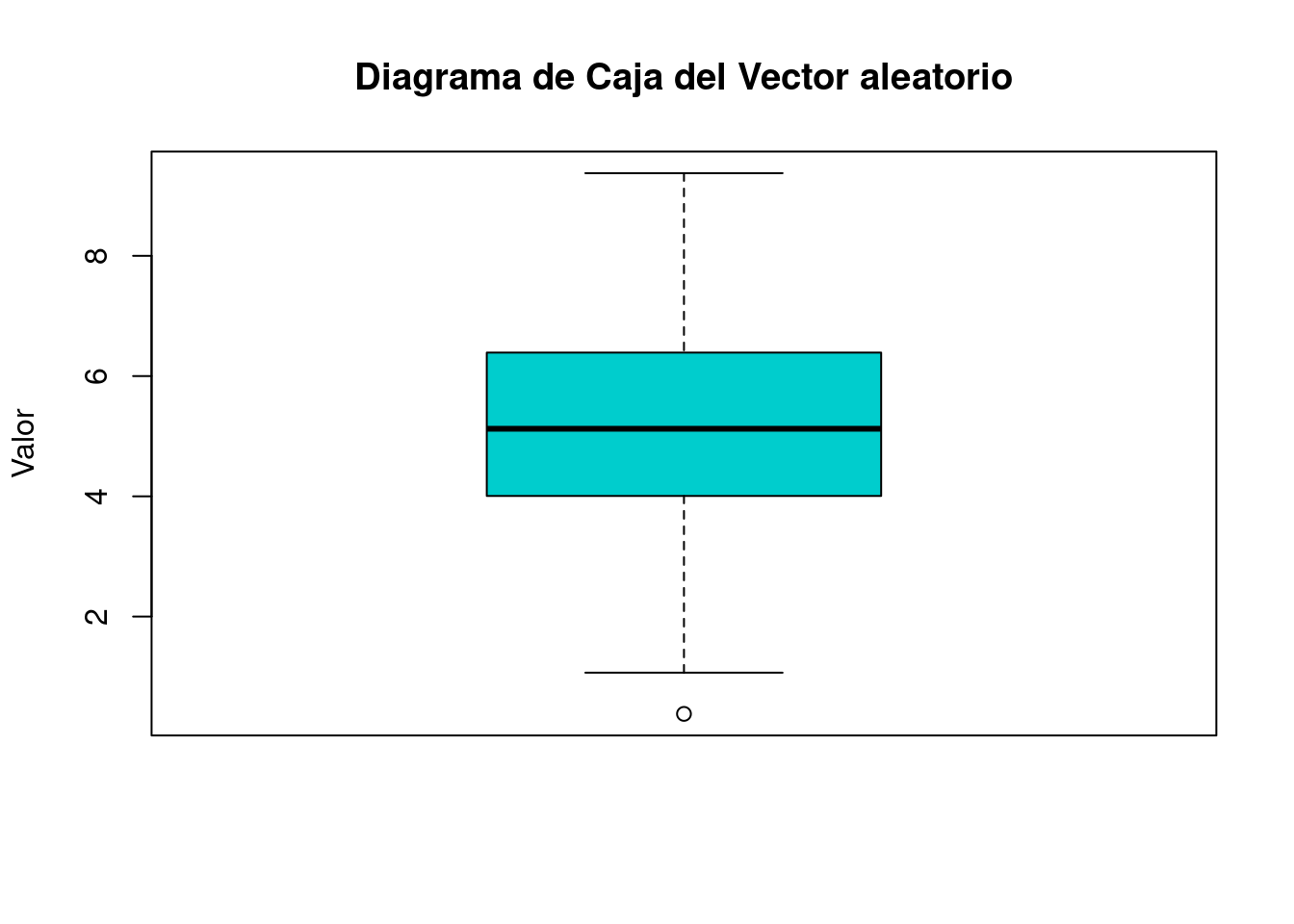
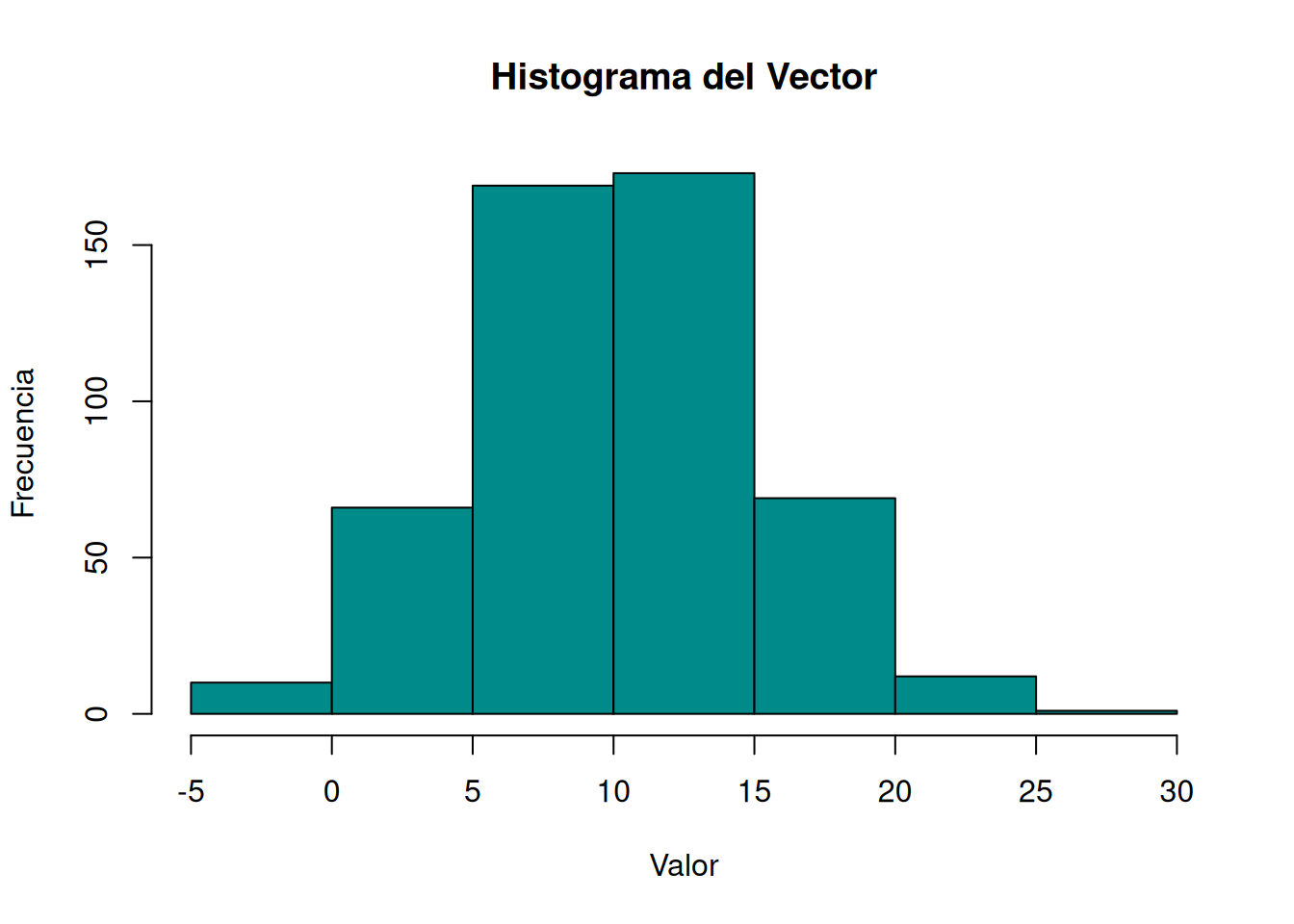
¿Cómo se vería la distribución de este vector aleatorio? Primero realizaremos un gráfico de histograma con la función hist y luego uno de cajas con la función boxplot.
hist(vector,main="Histograma del Vector",xlab="Valor",ylab="Frecuencia",col="cyan4",border="black")
boxplot(vector,main="Diagrama de Caja del Vector aleatorio",ylab="Valor",col="cyan3")
Ahora, calculamos la media y la desviación estándar del vector:
media <-mean(vector)desv_estandar <-sd(vector)cat("Media:", media, "\n")
Media: 5.180812
cat("Desviación Estándar:", desv_estandar, "\n")
Desviación Estándar: 1.825632
En el caso de nuestro vector, creado con datos aleatorios, la media \(\bar{x} = 5,18\) nos muestra que el promedio de los datos se encuentra en torno a 5,2.
La desviación estándar corresponde, entonces, a un promedio de lo que cada valor se aleja del promedio del vector. En el caso de nuestro vector, \(s = 1,82\) nos muestra que en promedio los datos se alejan 1,82 puntos del promedio.
2. Puntajes Z
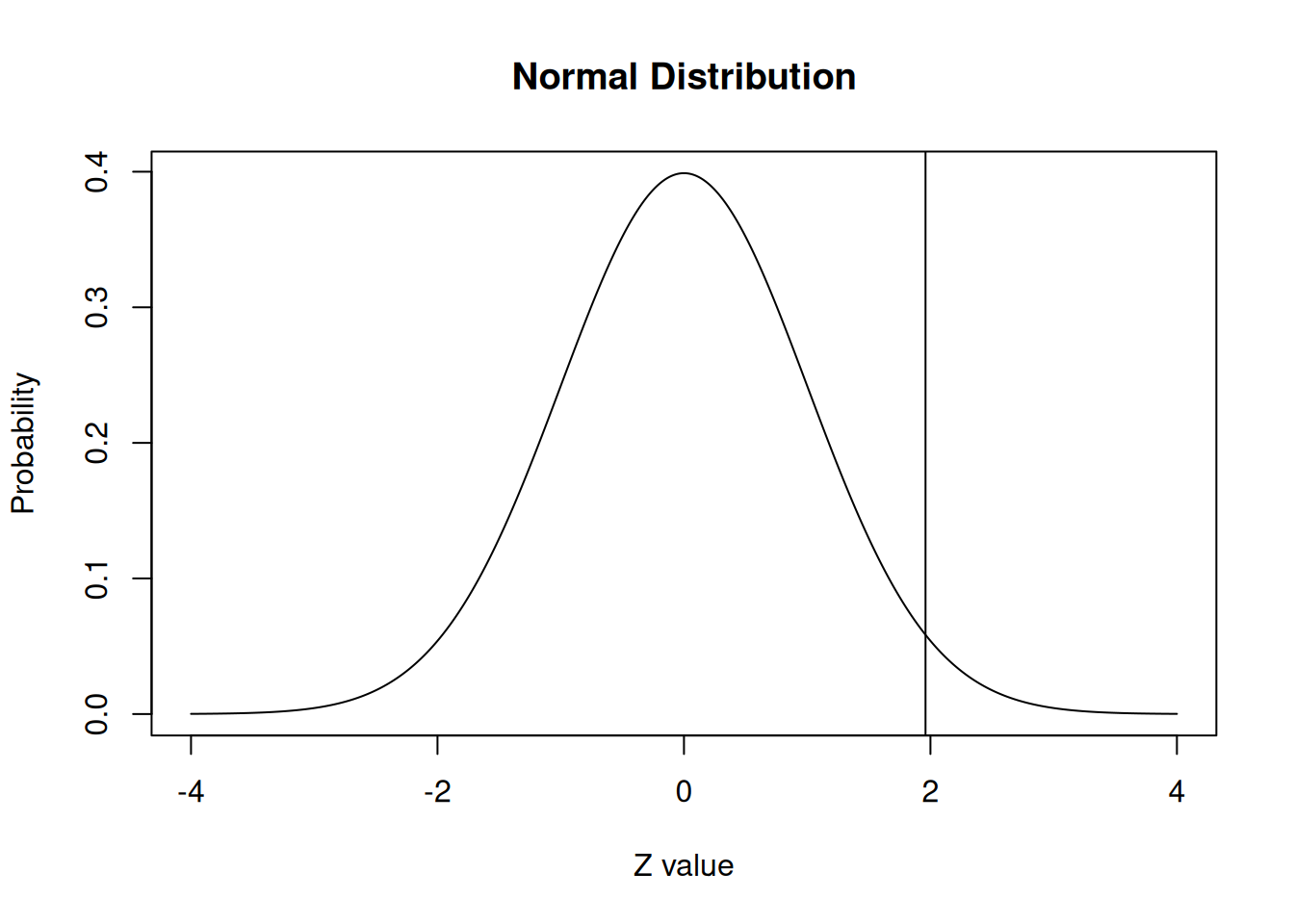
Al estandarizar las variables (como en la Curva Normal Estándar) lo que hacemos es expresar el valor de una distribución en términos de desviaciones estándar basados en la distribución normal. Esto nos permite comparar distribuciones distintas.
Al valor estandarizado lo llamamos puntaje Z, y corresponde a la cantidad de desviaciones estándar que nos alejamos del promedio (para cada variable con la que trabajemos).
2.1. Cálculo de probabilidades con puntaje Z
# Estandarizar el vectorz_scores <-scale(vector)# Comparar valores originales y estandarizadoshead(data.frame(Valor=vector, Z=z_scores), 10)
Podemos preguntar qué parte de la curva cae por debajo de un valor particular. Por ejemplo, preguntaremos sobre el valor 0 antes de ejecutar el código. Piense ¿cuál debería ser la respuesta?
# Probabilidades acumuladaspnorm(0) # P(Z <= 0)
[1] 0.5
Ahora probemos los valores Z de +1,96 y -1,96.
Sabemos que estos valores aproximados marcan el 2,5% superior e inferior de la distribución normal estándar. Esto corresponde a un alfa típico \(\alpha = 0,05\) para una prueba de hipótesis de dos colas.
pnorm(1.96) # P(Z <= 1.96)
[1] 0.9750021
pnorm(-1.96) # P(Z <= -1.96)
[1] 0.0249979
La respuesta nos dice lo que ya sabemos: el 97,5% de la distribución normal ocurre por debajo del valor z de 1,96.
Un intervalo de confianza es un rango dentro del cual es probable que se encuentre un parámetro poblacional con un nivel de confianza específico. Además, proporciona información sobre la precisión de nuestras estimaciones.
3.1. Cálculo de intervalos de confianza para medias
En el caso de nuestro vector aleatorio, un intervalo de confianza para la media se puede calcular de dos maneras:
Primero, con la función t.test que, por defecto, estima el intervalo de confianza del 95%
# Calcular un intervalo de confianza para la mediaintervalo_confianza <-t.test(vector)$conf.int # Intervalo de confianza del 95% para la mediaintervalo_confianza
Otra opción es con la función ci.mean del paquete Publish. Con esta función también podemos especificar si queremos estimar los CI al 95% (alpha = 0.05) o al 99% (alpha = 0.05)
Publish::ci.mean(vector, alpha =0.05)
mean CI-95%
5.18 [4.82;5.54]
Contamos con una media 5.18 como estimación puntual. Pero también podemos decir que con un 95% de confianza el parámetro poblacional se encontrará entre 4.82 y 5.54.
Publish::ci.mean(vector, alpha =0.01)
mean CI-99%
5.18 [4.70;5.66]
Contamos con una media 5.18 como estimación puntual. Pero también podemos decir que con un 99% de confianza el parámetro poblacional se encontrará entre 4.70 y 5.66.
Resumen
Hoy pudimos aprender y recordar:
Los conceptos de promedio y dispersión
Estimación de puntajes Z
Cálculo de intervalos de confianza
Ejercicio práctico de trabajo autónomo
En este ejercicio aplicara los tres pasos vistos en el taller: cálculo de media y desviación estándar, puntajes Z e intervalos de confianza, pero con nuevos datos simulados.
Instrucciones
Genere un vector de datos simulados
Cree un vector con 500 observaciones distribuidas normalmente
Debe tener \(\mu = 10\) y \(\sigma = 5\)
set.seed(123) # Fijar la semilla para reproducibilidadvector2 <-rnorm(500, mean =10, sd =5) # cambiamos a vector2 para no confundir con el otro
Calcule y describa la distribución
Obtenga la media y desviación estándar de su vector.
media <-mean(vector2)desv_estandar <-sd(vector2)cat("Media:", media, "\n")
Media: 10.17295
cat("Desviación Estándar:", desv_estandar, "\n")
Desviación Estándar: 4.863847
Visualice la distribución en un histograma
hist(vector2,main="Histograma del Vector",xlab="Valor",ylab="Frecuencia",col="cyan4",border="black")
Estandarice los datos (puntajes Z)
Transforme tu vector a puntajes Z usando scale().
z_scores2 <-scale(vector2)
Muestre los primeros 10 valores (head()).
# Comparar valores originales y estandarizadoshead(data.frame(Valor=vector2, Z=z_scores2), 10)
¿Cuál es el máximo puntaje Z y el mínimo puntaje Z?
max_z <-max(z_scores2)min_z <-min(z_scores2)
Verifique la media y sd
mean(z_scores2) # Debe ser 0
[1] -1.457272e-16
sd(z_scores2) # Debe ser 1
[1] 1
Calcule el intervalo de confianza (IC 95%) para la media
Estime el IC para un 95% de confianza
# Calcular un intervalo de confianza para la mediaintervalo_confianza <-t.test(vector2)$conf.int # Intervalo de confianza del 95% para la mediaintervalo_confianza