pacman::p_load(tidyverse, # Manipulacion datos
sjPlot, # Graficos y tablas
sjmisc, # Descriptivos
corrplot, # Correlaciones
psych, # Test estadísticos
kableExtra) # Tablas
options(scipen = 999) # para desactivar notacion cientifica
rm(list = ls()) # para limpiar el entorno de trabajoPráctico 4: Matrices de correlación, casos pérdidos e índices
Sesión del miércoles, 8 de octubre de 2025
Objetivo de la práctica
El objetivo de esta guía práctica es conocer maneras de reportar coeficientes de correlación y otras medidas de correlación para variables ordinales. Además, nos introduciremos en el tratamiento de valores perdidos y generación de índices. Todo ello a partir de una pregunta de investigación empírica.
En detalle, aprenderemos a:
- Estimar e interpretar coeficientes de correlación de Spearman y Kendall
- Generar y reportar matrices de correlación
- Tratamiento de casos perdidos
- Analizar baterías de indicadores y generar índices
En esta guía utilizaremos un ejemplo que desarrollaremos progresivamente para exponer los contenidos. Al final de esta guía se proporciona un ejercicio autónomo que deberá resolver de manera individual o grupal tomando como referencia el ejemplo aquí expuesto.
1. Pregunta de investigación
El aumento de la desigualdad económica y la concentración de la riqueza se han vinculado al resurgimiento de diversos conflictos sociales a nivel global. En este contexto, varios estudios han explorado en qué medida los individuos perciben conflictos sociales entre grupos, especialmente aquellos organizados verticalmente en la estructura social, como ricos-pobres o trabajadores-empresarios (Edlund & Lindh, 2015; Hadler, 2017).
Sin embargo, en la literatura existe poca evidencia sobre cómo la percepción de desigualdad afecta las percepciones de conflicto social ni se ha examinado la consistencia de los indicadores utilizados para medirlas. Estas preguntas las responderemos estudiando el caso de Chile, un país que se caracteriza por sus altos niveles de desigualdad económica y concentración de la riqueza (Chancel et al., 2022).
Pregunta 1: ¿En qué medida se relacionan la percepción de desigualdad y la percepción de conflictos sociales en Chile?
Pregunta 2: ¿Cómo se relacionan los distintos indicadores utilizados para medir la percepción de conflictos sociales?
Recursos de la práctica
En esta práctica trabajaremos con un subconjunto de datos previamente procesados derivados de las encuesta del Módulo de Desigualdad Social de la International Social Survey Programme (ISSP) para Chile del año 2009. Para este ejercicio, obtendremos directamente esta base desde internet. No obstante, también es posible acceder a la misma información a través del siguiente enlace: ISSP Chile 2009. Desde allí, podrás descargar el archivo que contiene el subconjunto procesado de la base de datos ISSP 2009 para Chile.
2. Datos y librerías
Comencemos por preparar nuestros datos. Iniciamos cargando las librerías necesarias.
Cargamos los datos directamente desde internet.
# Cargar bbdd desde internet
load(url("https://github.com/cursos-metodos-facso/datos-ejemplos/raw/refs/heads/main/issp_2009_chile.RData"))A continuación, exploramos el subset de datos issp.
names(issp) # Nombre de columnas [1] "sex" "age" "educyrs" "income"
[5] "topbot" "pref_redis" "perc_ineq" "conflict_rp"
[9] "conflict_wcmc" "conflict_mw" "conflict_tb" dim(issp) # Dimensiones[1] 1505 11Contamos con 11 variables (columnas) y 1505 observaciones (filas).
Ahora, realizaremos un pequeño procesamiento de nuestros datos con dplyr, todo de una vez mediante el uso de pipes %>%. Para recordar los pasos para el procesamiento de datos, revisar la guía práctica del curso de estadística descriptiva.
proc_issp <- issp %>% # seleccionamos
dplyr::select(age,
educyrs,
income,
topbot,
perc_ineq,
starts_with("conflict")) Ahora, exploremos estadísticos descriptivos de nuestra base procesada proc_issp
proc_issp %>%
sjmisc::descr(show = c("label","range", "mean", "sd", "NA.prc", "n")) %>%
kable(.,"markdown")| var | label | n | NA.prc | mean | sd | range | |
|---|---|---|---|---|---|---|---|
| 1 | age | Edad | 1505 | 0.0000000 | 46.561462 | 17.6353912 | 73 (18-91) |
| 6 | educyrs | Nivel educativo | 1451 | 3.5880399 | 10.762922 | 4.4097420 | 24 (1-25) |
| 7 | income | Decil ingreso | 1146 | 23.8538206 | 5.489529 | 2.8723002 | 9 (1-10) |
| 9 | topbot | Estatus social subjetivo | 1490 | 0.9966777 | 4.025503 | 1.6599884 | 9 (1-10) |
| 8 | perc_ineq | Percepción desigualdad | 1492 | 0.8637874 | 4.188338 | 0.8271374 | 4 (1-5) |
| 3 | conflict_rp | Conflictos: ricos - pobres | 1438 | 4.4518272 | 2.613352 | 0.8665370 | 3 (1-4) |
| 5 | conflict_wcmc | Conflictos: clase trabajadora - clase media | 1426 | 5.2491694 | 2.289621 | 0.8965377 | 3 (1-4) |
| 2 | conflict_mw | Conflictos: directivos - trabajadores | 1427 | 5.1827243 | 2.714085 | 0.8304120 | 3 (1-4) |
| 4 | conflict_tb | Conflictos: gente de arriba - gente de abajo | 1425 | 5.3156146 | 2.661754 | 0.9044854 | 3 (1-4) |
3. Análisis
La manera en que se miden las variables de percepción de conflictos y percepción de desigualdad en la ISSP 2009 para Chile es la siguiente:
Percepción de conflictos: En todos los países hay diferencias o incluso conflictos entre diferentes grupos sociales. En su opinión, ¿Cuánto conflicto hay en Chile hoy en día entre…?
| Ítem | Categorías de respuesta |
|---|---|
| A. La gente pobre y la gente rica | Conflictos muy fuertes (1); Conflictos fuertes (2); Conflictos no muy fuertes (3); No hay conflictos (4) |
| B. La clase trabajadora y la clase media | Conflictos muy fuertes (1); Conflictos fuertes (2); Conflictos no muy fuertes (3); No hay conflictos (4) |
| C. La gerencia y los trabajadores | Conflictos muy fuertes (1); Conflictos fuertes (2); Conflictos no muy fuertes (3); No hay conflictos (4) |
| D. La gente en el nivel más alto de la sociedad y la gente en el nivel más bajo | Conflictos muy fuertes (1); Conflictos fuertes (2); Conflictos no muy fuertes (3); No hay conflictos (4) |
Percepción de desigualdad: Qué tan de acuerdo o en desacuerdo está UD. con las siguientes afirmaciones?
| Ítem | Categorías de respuesta |
|---|---|
| A. Las diferencias de ingreso en Chile son demasiado grandes | Muy de acuerdo (1); De acuerdo (2); Ni de acuerdo ni en desacuerdo (3); En desacuerdo (4); Muy en desacuerdo (5) |
Todas estas variables fueron recodificadas inversamente para este ejercicio.
Nota
Entonces, ¿qué herrramienta usar?
Pregunta 1: Dado que las variables de percepción de conflictos y percepción de desigualdad son de nivel de medición ordinal, podemos estimar su asociación con coeficientes de correlación para variables ordinales.
Pregunta 2: Podemos estimar una matriz de correlaciones entre las variables de percepción de conflictos tratando los casos pérdidos. Luego, podemos estimar la consistencia interna (alpha de Cronbach) para generar un índice promedio.
3.1 Correlación para variables ordinales
3.1.1 Coeficiente de correlación de Spearman
En R calcularlo es sencillo, pero debemos tener en cuenta que las variables que relacionemos tengan un orden de rango similar: por ejemplo, que el valor más bajo sea el rango más bajo y que el valor más alto sea el rango más alto.
Observemos las frecuencias de las variables conflict_rp (conflictos ricos-pobres) y perc_ineq (percepción desigualdad)
sjmisc::frq(proc_issp$conflict_rp)Conflictos: ricos - pobres (x) <numeric>
# total N=1505 valid N=1438 mean=2.61 sd=0.87
Value | N | Raw % | Valid % | Cum. %
--------------------------------------
1 | 161 | 10.70 | 11.20 | 11.20
2 | 442 | 29.37 | 30.74 | 41.93
3 | 627 | 41.66 | 43.60 | 85.54
4 | 208 | 13.82 | 14.46 | 100.00
<NA> | 67 | 4.45 | <NA> | <NA>sjmisc::frq(proc_issp$perc_ineq)Percepción desigualdad (x) <numeric>
# total N=1505 valid N=1492 mean=4.19 sd=0.83
Value | N | Raw % | Valid % | Cum. %
--------------------------------------
1 | 16 | 1.06 | 1.07 | 1.07
2 | 65 | 4.32 | 4.36 | 5.43
3 | 105 | 6.98 | 7.04 | 12.47
4 | 742 | 49.30 | 49.73 | 62.20
5 | 564 | 37.48 | 37.80 | 100.00
<NA> | 13 | 0.86 | <NA> | <NA>Ahora, calculemos el coeficiente de correlación de Spearman con cor.test.
cor.test(proc_issp$conflict_rp, proc_issp$perc_ineq, method = "spearman") #especificamos metodo spearman
Spearman's rank correlation rho
data: proc_issp$conflict_rp and proc_issp$perc_ineq
S = 430911455, p-value = 0.000008055
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.1176912 Ahora conocemos el valor del coeficiente de Spearman mediante al argumento rho, que es igual a 0.12, siendo positivo y pequeño según los criterios de Cohen (1988).
3.1.2 Coeficiente de correlación Tau de Kendall
Recomendado cuando hay un set de datos pequeños y/o cuando hay mucha repetición de observaciones en el mismo ranking. Se basa en una comparación de pares de observaciones concordantes y discordantes.
Ahora, calculemos el coeficiente de correlación Tau de Kendall con cor.test.
cor.test(proc_issp$conflict_rp, proc_issp$perc_ineq, method = "kendall") #especificamos metodo kendall
Kendall's rank correlation tau
data: proc_issp$conflict_rp and proc_issp$perc_ineq
z = 4.4558, p-value = 0.000008358
alternative hypothesis: true tau is not equal to 0
sample estimates:
tau
0.1043735 El valor del coeficiente de Kendall mediante al argumento tau, es igual a 0.1, siendo positivo y pequeño según los criterios de Cohen (1988).
¿PERO QUÉ HACER CON LOS CASOS PERDIDOS?
3.2 Tratamiento de casos perdidos
Existen varias formas de tratar valores perdidos, que van desde enfoques simples hasta métodos más complejos, como la imputación. En esta ocasión, nos centraremos en las dos estrategias más comunes:
- trabajar exclusivamente con casos completos (listwise) o
- retener los casos con valores perdidos, pero excluyéndolos al calcular estadísticas (pairwise).
3.2.1 Analísis con casos completos: listwise deletion
Este enfoque es uno de los más conocidos: implica remover completamente las observaciones que tienen valores perdidos en cualquier variable de interés. En otras palabras, si una fila/caso en un conjunto de datos tiene al menos un valor faltante en alguna de las variables que estás considerando, se eliminará por completo.
En R, esto podemos hacerlo con la función na.omit. Para hacer esto, sigamos estos pasos:
- respaldar la base de datos original en el espacio de trabajo (por si queremos en adelante realizar algún análisis referido a casos perdidos)
- contamos el número de casos con el comando
dim. - contamos cuántos y en dónde tenemos casos perdidos.
- borramos los casos perdidos con
na.omit. - contamos nuevamente con
dimpara asegurarnos que se borraron.
proc_issp_original <- proc_issp
dim(proc_issp)[1] 1505 9sum(is.na(proc_issp))[1] 745colSums(is.na(proc_issp)) age educyrs income topbot perc_ineq
0 54 359 15 13
conflict_rp conflict_wcmc conflict_mw conflict_tb
67 79 78 80 proc_issp <- na.omit(proc_issp)
dim(proc_issp)[1] 1021 9Ahora nos quedamos con 1021 observaciones sin casos perdidos.
Aunque simple de implementar, con este enfoque podemos perder información importante, especialmente si los valores perdidos no se distribuyen aleatoriamente.
Siempre hay que intentar rescatar la mayor cantidad de casos posibles. Por lo tanto, si un listwise genera más de un 10% de casos perdidos se debe detectar qué variables esta produciendo esta pérdida e intentar recuperar datos. Puedes revisar un ejemplo aquí.
3.2.2 Retener pero excluir: pairwise deletion
Para hacer esto en R debemos siempre verificar e indicar en nuestro código si queremos (o no) remover los NA para realizar los análisis.
mean(proc_issp_original$conflict_rp); mean(proc_issp_original$perc_ineq)[1] NA[1] NAmean(proc_issp_original$conflict_rp, na.rm = TRUE); mean(proc_issp_original$perc_ineq, na.rm = TRUE)[1] 2.613352[1] 4.188338Con el primer código no obtuvimos información sustantiva en ciertas variables, pero con el segundo sí al remover los NA solo de dicha variable para un cálculo determinado.
3.3 Matrices de correlación
En su forma simple en R se aplica la función cor a la base de datos, y la guardamos en un objeto que le damos el nombre M para futuras operaciones:
M <- cor(proc_issp_original, use = "complete.obs")
M age educyrs income topbot perc_ineq
age 1.000000000 -0.38639503 -0.028812258 -0.13419732 -0.05862427
educyrs -0.386395026 1.00000000 0.429527855 0.40464701 0.05369064
income -0.028812258 0.42952785 1.000000000 0.31867065 0.05266991
topbot -0.134197318 0.40464701 0.318670648 1.00000000 -0.04046890
perc_ineq -0.058624269 0.05369064 0.052669910 -0.04046890 1.00000000
conflict_rp -0.021976042 -0.08653773 -0.062332705 -0.09543086 0.07244029
conflict_wcmc 0.027803884 -0.13270803 -0.127695665 -0.10271518 -0.02023346
conflict_mw -0.007098218 -0.00320080 -0.009719637 -0.08839869 0.09639380
conflict_tb -0.017972485 -0.01935586 -0.006374423 -0.07742800 0.09545628
conflict_rp conflict_wcmc conflict_mw conflict_tb
age -0.02197604 0.02780388 -0.007098218 -0.017972485
educyrs -0.08653773 -0.13270803 -0.003200800 -0.019355856
income -0.06233270 -0.12769567 -0.009719637 -0.006374423
topbot -0.09543086 -0.10271518 -0.088398687 -0.077427998
perc_ineq 0.07244029 -0.02023346 0.096393796 0.095456283
conflict_rp 1.00000000 0.49981470 0.494650501 0.666310943
conflict_wcmc 0.49981470 1.00000000 0.448317804 0.413692854
conflict_mw 0.49465050 0.44831780 1.000000000 0.524011301
conflict_tb 0.66631094 0.41369285 0.524011301 1.000000000Este es el reporte simple, pero no muy amigable a la vista. Para una versión más reportable, utilizamos la función tab_corr.
sjPlot::tab_corr(proc_issp_original,
triangle = "lower")| Edad | Nivel educativo | Decil ingreso | Estatus social subjetivo | Percepción desigualdad | Conflictos: ricos - pobres | Conflictos: clase trabajadora - clase media |
Conflictos: directivos - trabajadores | Conflictos: gente de arriba - gente de abajo |
|
| Edad | |||||||||
| Nivel educativo | -0.386*** | ||||||||
| Decil ingreso | -0.029 | 0.430*** | |||||||
| Estatus social subjetivo | -0.134*** | 0.405*** | 0.319*** | ||||||
| Percepción desigualdad | -0.059 | 0.054 | 0.053 | -0.040 | |||||
| Conflictos: ricos - pobres | -0.022 | -0.087** | -0.062* | -0.095** | 0.072* | ||||
| Conflictos: clase trabajadora - clase media |
0.028 | -0.133*** | -0.128*** | -0.103** | -0.020 | 0.500*** | |||
| Conflictos: directivos - trabajadores | -0.007 | -0.003 | -0.010 | -0.088** | 0.096** | 0.495*** | 0.448*** | ||
| Conflictos: gente de arriba - gente de abajo |
-0.018 | -0.019 | -0.006 | -0.077* | 0.095** | 0.666*** | 0.414*** | 0.524*** | |
| Computed correlation used pearson-method with listwise-deletion. | |||||||||
La distinción entre listwise y pairwise es relevante al momento de estimar matrices de correlación, donde esta decisión debe estar claramente explicitada y fundamentada. En el ejemplo de tabla anterior usamos listwise que es el argumento por defecto (y nos lo indica al final de la tabla).
Veamos cómo hacerlo con pairwise:
sjPlot::tab_corr(proc_issp_original,
na.deletion = "pairwise", # espeficicamos tratamiento NA
triangle = "lower")| Edad | Nivel educativo | Decil ingreso | Estatus social subjetivo | Percepción desigualdad | Conflictos: ricos - pobres | Conflictos: clase trabajadora - clase media |
Conflictos: directivos - trabajadores | Conflictos: gente de arriba - gente de abajo |
|
| Edad | |||||||||
| Nivel educativo | -0.382*** | ||||||||
| Decil ingreso | -0.065* | 0.429*** | |||||||
| Estatus social subjetivo | -0.138*** | 0.402*** | 0.326*** | ||||||
| Percepción desigualdad | -0.070** | 0.057* | 0.041 | -0.034 | |||||
| Conflictos: ricos - pobres | -0.036 | -0.068* | -0.057 | -0.094*** | 0.087*** | ||||
| Conflictos: clase trabajadora - clase media |
0.018 | -0.139*** | -0.122*** | -0.118*** | -0.025 | 0.518*** | |||
| Conflictos: directivos - trabajadores | -0.040 | -0.016 | -0.005 | -0.079** | 0.100*** | 0.499*** | 0.438*** | ||
| Conflictos: gente de arriba - gente de abajo |
-0.049 | -0.037 | 0.007 | -0.076** | 0.089*** | 0.651*** | 0.441*** | 0.527*** | |
| Computed correlation used pearson-method with pairwise-deletion. | |||||||||
Con esta mejor visualización, algunas observaciones sobre la matriz de correlaciones:
- En esta matriz las variables están representadas en las filas y en las columnas.
- Cada coeficiente expresa la correlación de una variable con otra. Por ejemplo, la correlación entre la variable de
educyrsyincomees 0.43. - La información de cada coeficiente se repite sobre y bajo la diagonal, ya que es el mismo par de variables pero en el orden alterno. Por convención en general se omiten las correlaciones redundantes sobre la diagonal, por eso aparece en blanco.
- En la diagonal corresponde que todos los coeficientes sean 1, ya que la correlación de una variable consigo misma es perfectamente positiva.
Otra manera de presentar matrices de correlación es mediante gráficos. Veamos un ejemplo con la función corrplot de la librería corrplot sobre nuestra matriz M ya creada.
diag(M) <- NA
corrplot::corrplot(M,
method = "color",
addCoef.col = "black",
type = "upper",
tl.col = "black",
col = colorRampPalette(c("#E16462", "white", "#0D0887"))(12),
bg = "white",
na.label = "-") 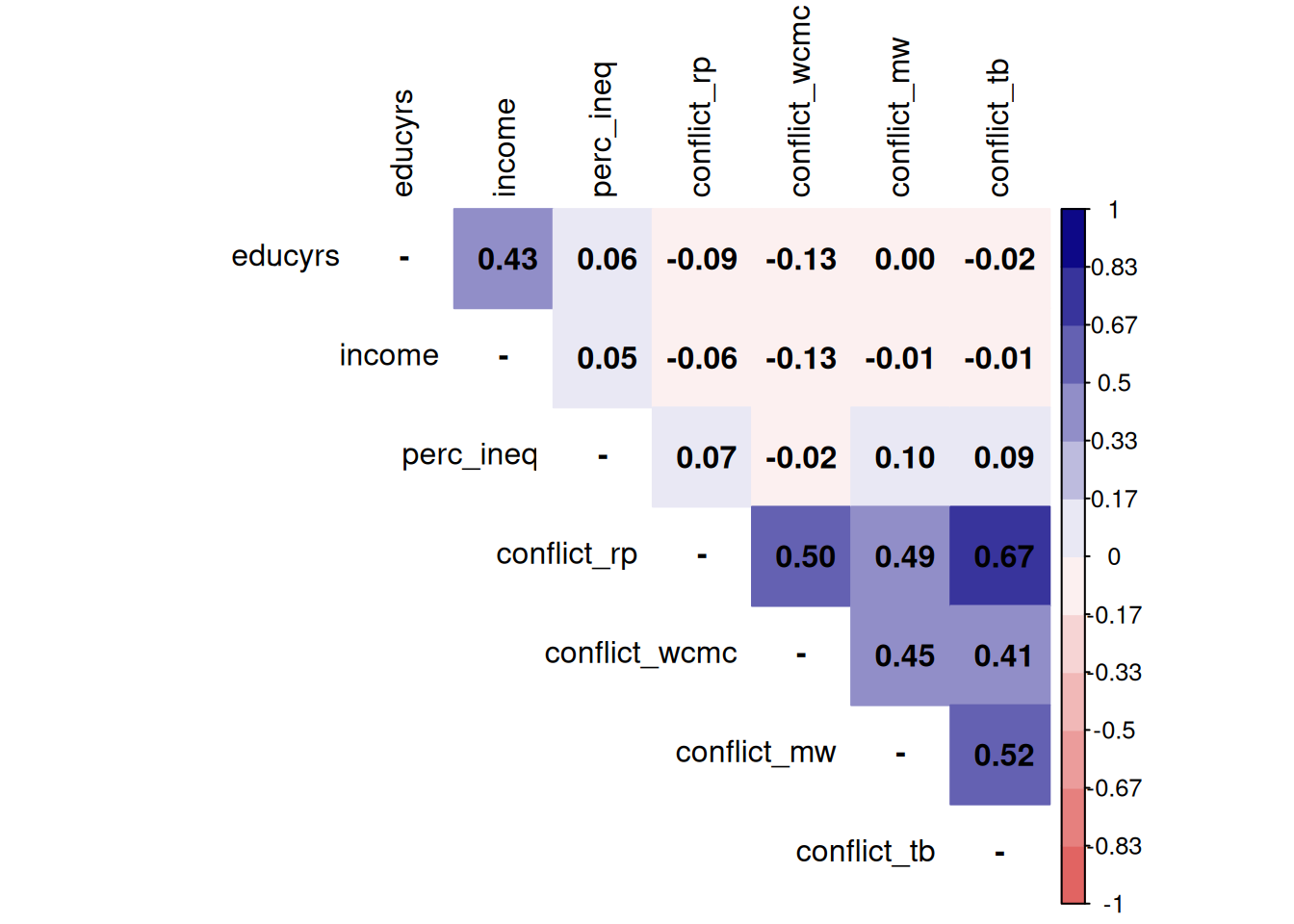
3.4 Baterías e índices
En la literatura sobre percepción de conflictos se suele utilizar un índice sumativo o promedio entre los distintos indicadores sobre conflictos percibidos: conflict_rp,conflict_wcmc,conflict_mw,conflict_tb.
Entonces, para poder responder nuestras preguntas de investigación, primero generaremos una matriz de correlaciones entre estos indicadores, luego evaluaremos su consistencia y generaremos el índice psci. Finalmente, realizaremos un test de correlación para examinar la asociación entre psci y perc_ineq.
M_psci <- proc_issp %>%
dplyr::select(starts_with("conflict"))
sjPlot::tab_corr(M_psci,
na.deletion = "listwise", # espeficicamos tratamiento NA
triangle = "lower")| Conflictos: ricos - pobres | Conflictos: clase trabajadora - clase media |
Conflictos: directivos - trabajadores | Conflictos: gente de arriba - gente de abajo |
|
| Conflictos: ricos - pobres | ||||
| Conflictos: clase trabajadora - clase media |
0.500*** | |||
| Conflictos: directivos - trabajadores | 0.495*** | 0.448*** | ||
| Conflictos: gente de arriba - gente de abajo |
0.666*** | 0.414*** | 0.524*** | |
| Computed correlation used pearson-method with listwise-deletion. | ||||
Los ítems se correlacionan de manera positiva y con tamaños de efecto moderados y altos para las ciencias sociales. Con ello, podemos pasar a evaluar sus relaciones tienen consistencia interna.
alpha_psci <- psych::alpha(M_psci)
alpha_psci$total$raw_alpha[1] 0.8043218De acuerdo con este resultado, el alpha de Cronbach reflejado en el raw_alpha del output es superior al estandar de 0.6 en ciencias sociales, por lo que se sostiene su consistencia.
Ahora, generemos el índice psci
proc_issp <- cbind(proc_issp, "psci" = rowMeans(proc_issp %>% select(starts_with("conflict")), na.rm=TRUE))
sjmisc::descr(proc_issp$psci, show = c("range", "mean", "sd", "NA.prc", "n")) %>%
kable(.,"markdown")| var | n | NA.prc | mean | sd | range |
|---|---|---|---|---|---|
| dd | 1021 | 0 | 2.584966 | 0.6986975 | 3 (1-4) |
4. Conclusiones
Pregunta 1
¿En qué medida se relacionan la percepción de desigualdad y la percepción de conflictos sociales en Chile?
Realicemos la prueba estadística correspondiente.
cor.test(proc_issp$psci, proc_issp$perc_ineq, method = "pearson", use = "complete.obs")
Pearson's product-moment correlation
data: proc_issp$psci and proc_issp$perc_ineq
t = 2.4371, df = 1019, p-value = 0.01497
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.01484301 0.13683850
sample estimates:
cor
0.07612564 De acuerdo a este resultado, la correlación de Pearson entre la percepción de conflicto social y la percepción de desigualdad es positiva, muy pequeña y estadísticamente significativa (\(r\) = 0.07, \(p\) < 0.05).
Pregunta 2
¿Cómo se relacionan los distintos indicadores utilizados para medir la percepción de conflictos sociales?
De acuerdo al resultado de la matriz de correlaciones y del alpha de Cronbach, los indicadores utilizados para medir la percepción de conflictos se relacionan positiva y significativamente (\(p\) < 0.05), además de demostrar un nivel de consistencia interna aceptable (\(\alpha\) = 0.8).
Video de la sesión
Ejercicio autónomo
A partir de la base de datos de proc_issp responda la siguiente pregunta ¿en qué medida la percepción de conflictos se asocia con el estatus socioeconómico de las personas? Para responder esta pregunta siga los siguientes pasos:
- Estime y reporte una matriz de correlación con las variables
income,educyrsytopbot. Considere el tratamiento de casos perdidos.
proc_issp %>% dplyr::select(income, educyrs, topbot) %>%
sjPlot::tab_corr(,
na.deletion = "listwise", # espeficicamos tratamiento NA
triangle = "lower")| Decil ingreso | Nivel educativo | Estatus social subjetivo | |
| Decil ingreso | |||
| Nivel educativo | 0.430*** | ||
| Estatus social subjetivo | 0.319*** | 0.405*** | |
| Computed correlation used pearson-method with listwise-deletion. | |||
- Calcule el alpha de cronbach de la matriz del punto anterior.
alpha_ses <- proc_issp %>%
dplyr::select(income, educyrs, topbot) %>%
psych::alpha()
alpha_ses$total$raw_alpha[1] 0.592009- Genere un índice promedio de estatus socioeconómico a partir de las variables utilizadas en la matriz y llámelo
ses.
proc_issp <- cbind(proc_issp, "ses" = rowMeans(proc_issp %>% dplyr::select(income, educyrs, topbot), na.rm=TRUE))- Calcule el coeficiente de correlación de Pearson (\(r\)) entre las variables
psciyses. Reporte e interprete sus resultados. ¿en qué medida la percepción de conflictos se asocia con el estatus socioeconómico de las personas?
cor(proc_issp$psci, proc_issp$ses)[1] -0.1009905- Estime y reporte una matriz de correlación con las variables
psci,ses,ageyperc_ineq. Interprete sentido, tamaño de efecto y significancia de las principales asociaciones
proc_issp %>% dplyr::select(psci, ses, age, perc_ineq) %>%
sjPlot::tab_corr(,
na.deletion = "listwise", # espeficicamos tratamiento NA
triangle = "lower")| psci | ses | Edad | Percepción desigualdad | |
| psci | ||||
| ses | -0.101** | |||
| Edad | -0.006 | -0.284*** | ||
| Percepción desigualdad | 0.076* | 0.045 | -0.059 | |
| Computed correlation used pearson-method with listwise-deletion. | ||||
- psci × ses (r = -0.101, p < .01)
Sentido: negativa — a mayor nivel socioeconómico, menor puntaje en psci.
Tamaño del efecto: pequeño (Cohen, 1988).
Significancia: estadísticamente significativa con un 99% de confianza (p < .01).
Interpretación: quienes tienen un nivel socioeconómico más alto tienden a mostrar ligeramente menores niveles de percepción de conflictos sociales (psci).
- edad × ses (r = -0.284, p < .001)
Sentido: negativa — personas de mayor edad tienden a tener menor ses.
Tamaño del efecto: moderado.
Significancia: estadísticamente significativa con un 99.9% de confianza (p < .001).
- psci × percepción de desigualdad (r = 0.076, p < .05)
Sentido: positiva — mayor psci se asocia con mayor percepción de desigualdad.
Tamaño del efecto: pequeño.
Significancia: estadísticamente significativa con un 95% de confianza (p < .05).
- Asociaciones no significativas:
edad × percepción de desigualdad (r = -0.059) y ses × percepción de desigualdad (r = 0.045) no son estadísticamente significativas, por lo que no hay evidencia suficiente de asociación en estos pares.
Referencias
Chancel, L., Piketty, T., Saez, E., & Zucman, G. (2022). World Inequality Report 2022.
Edlund, J., & Lindh, A. (2015). The Democratic Class Struggle Revisited: The Welfare State, Social Cohesion and Political Conflict. Acta Sociologica, 58(4), 311-328. https://doi.org/10.1177/0001699315610176
Hadler, M. (2017). Social Conflict Perception Between Long-Term Inequality and Short-Term Turmoil. 17, 16.